run() on a team, the leader decides how to handle the request: respond directly, use tools, or delegate to members.
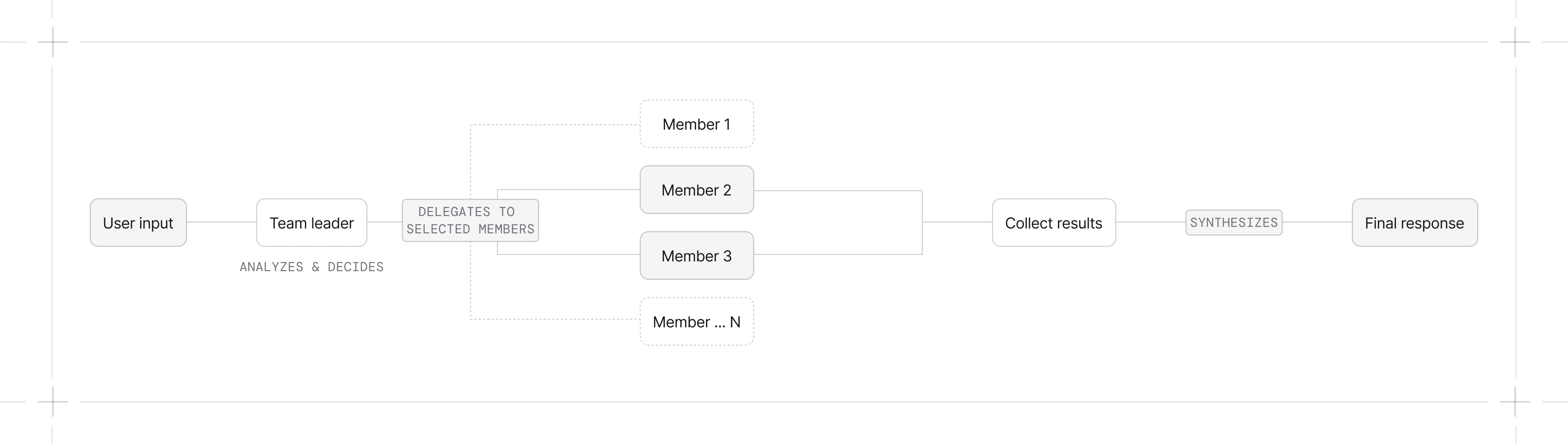
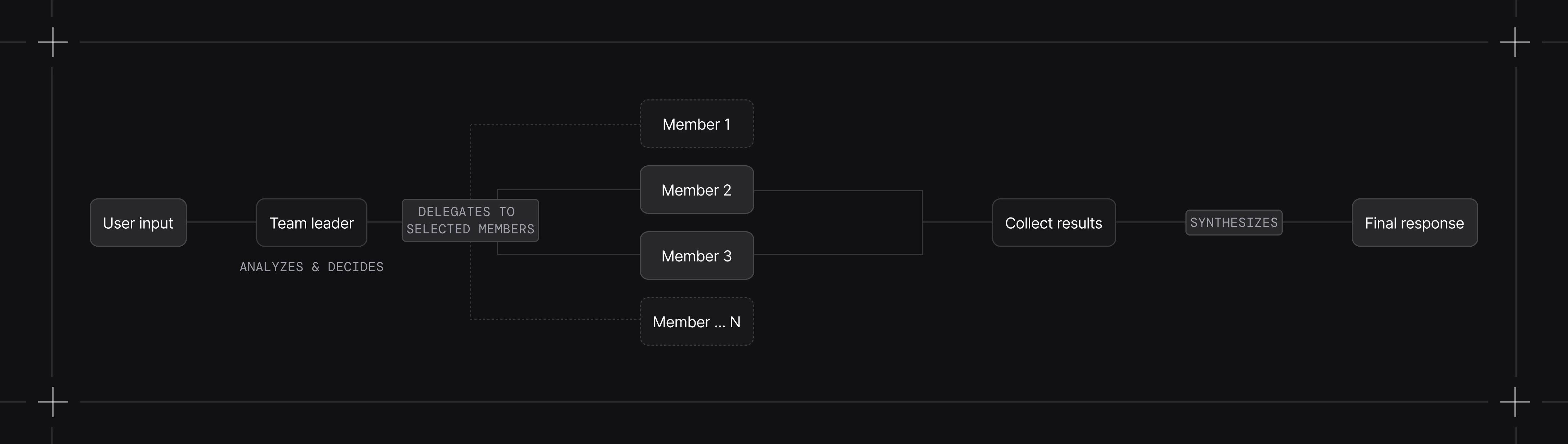
- Team receives user input
- Leader analyzes the input and decides which members to delegate to
- Leader formulates a task for each selected member
- Members execute and return results. Multiple async member calls can run concurrently.
- Leader synthesizes results into a final response
Use
TeamMode from agno.team.mode to set the mode explicitly. The leader can still answer directly or use its own tools. The legacy flags still work, but mode is the recommended approach.
Member selection and run tracking use member IDs. Set explicit id values on members for stable delegation identity.
Coordinate Mode (Default)
The leader selects members, writes their tasks, and combines their outputs.- Tasks need decomposition into subtasks
- You want quality control over the final output
- The leader should add context or reasoning to member outputs
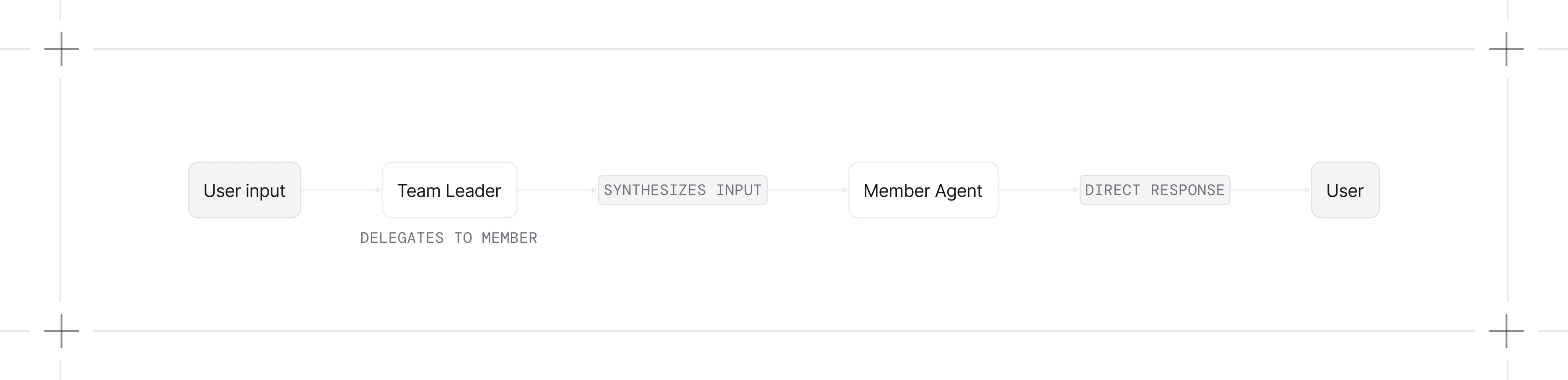
Route Mode
The leader selects which member handles the request and returns the member’s response directly. By default the leader can still craft the task; setdetermine_input_for_members=False to pass the user input through unchanged.
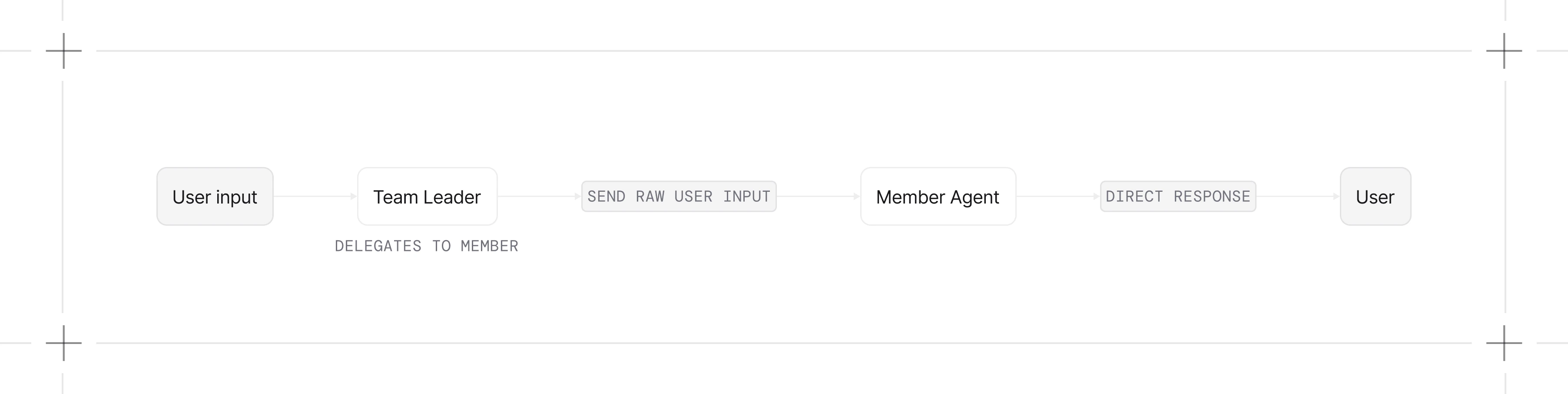
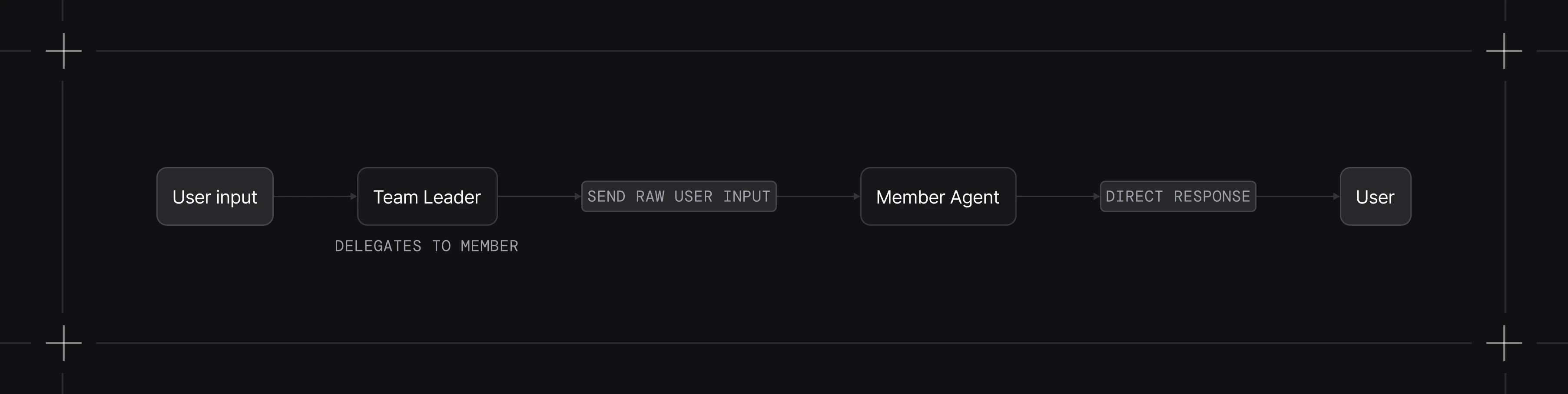
- You have specialized agents and want automatic routing
- The member should receive the request unchanged
- You want lower latency (no synthesis step)
Legacy Configuration Flags
These flags still work, but are overridden bymode when set.
respond_directly=True: Return member responses without leader synthesis (maps to TeamMode.route).
determine_input_for_members=False: Send the user-message content to members instead of having the leader formulate a task. This applies to coordinate, route, and broadcast delegation.


Broadcast Mode
The leader delegates the same task to all members. Synchronous runs execute members sequentially. Asynchronous runs execute them concurrently.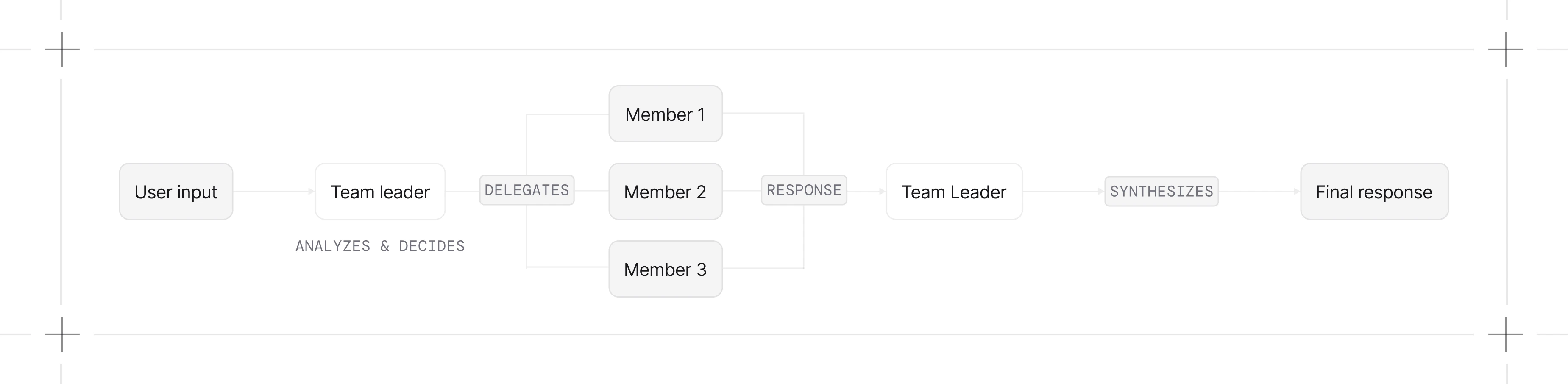
- You want multiple perspectives on the same topic
- Members can work independently
- You can use
arun()for concurrent member execution
If both
delegate_to_all_members=True and respond_directly=True are set and mode is not set, Agno logs a warning and disables respond_directly. The task is still delegated to all members, but team.mode reports TeamMode.route. Set mode explicitly instead of combining these flags.Tasks Mode
Tasks mode is an autonomous loop where the leader decomposes the goal into tasks, executes them, and marks the goal complete. The run stops if it reachesmax_iterations first.
Structured Input
When usingdetermine_input_for_members=False, a Pydantic input is serialized to JSON in the user-message content sent to members:
Production Considerations
Model Calls
Latency
- Coordinate: Selection and synthesis add leader model calls. Multiple async delegations can overlap.
- Route: Skips leader synthesis after a member is selected.
- Broadcast: Sync runs members sequentially. Async runs members concurrently before synthesis.
- Tasks: Runs multiple cycles until tasks are complete or
max_iterationsis reached.
Error Handling
Member and team retries are configured separately. InspectTeamToolCallError, TeamRunError, member events, and member responses instead of assuming a partial result is complete. Test failure behavior for the selected mode and sync or async path.