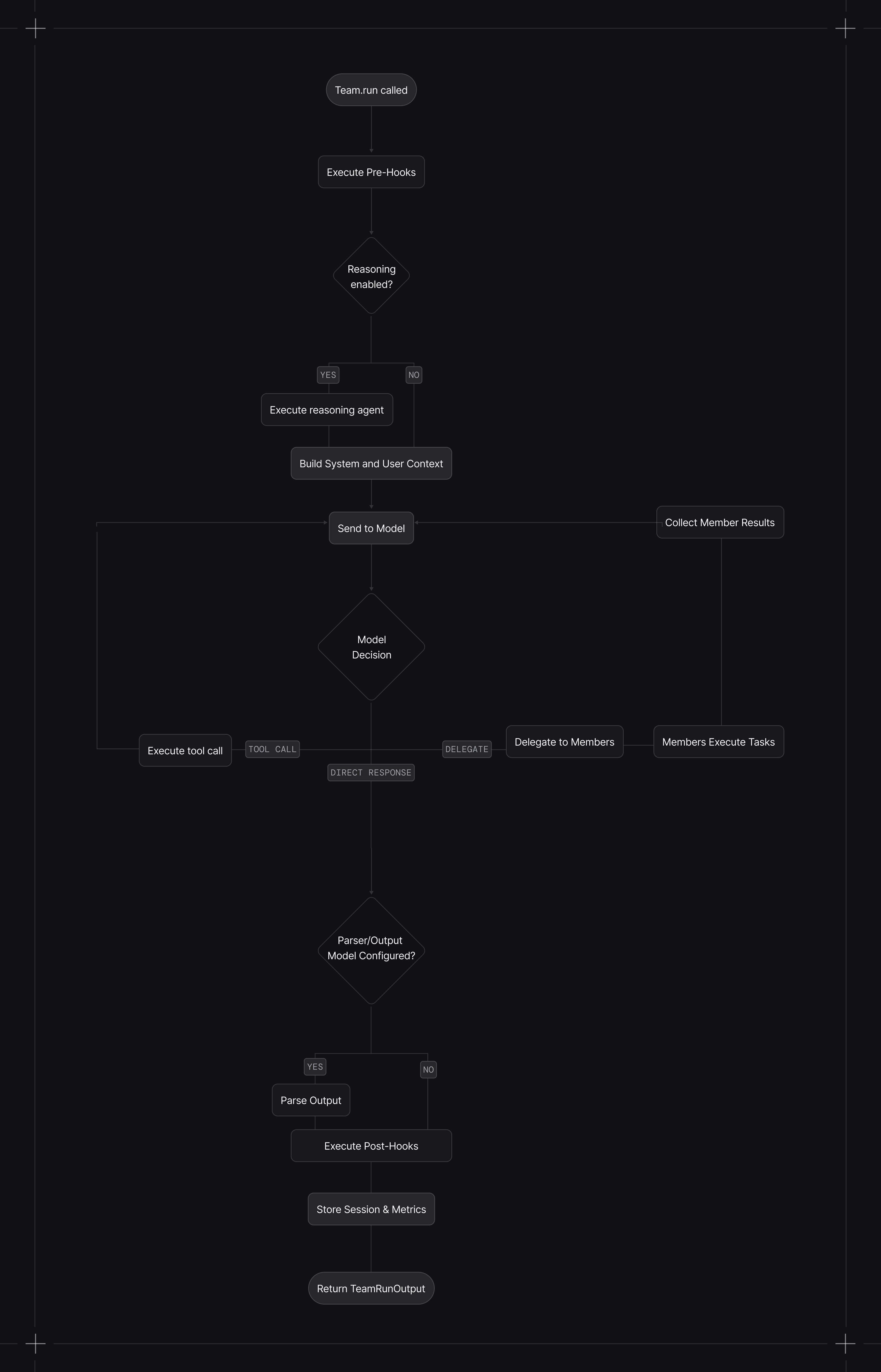
Context is built with system message, history, memories, and session state
Model decides whether to respond directly, use tools, or delegate to members
Members execute their tasks (concurrently in async mode)
Leader synthesizes member results into a final response
Post-hooks execute (if configured)
Session and metrics are stored (if database configured)
Callable factories are resolved after session state is loaded, so factories can access run_context and session_state. Async factories require arun() or aprint_response().
Mode
Execution style
coordinate
Leader decomposes work, delegates to members, synthesizes results
route
Leader routes to one member and returns the member response
broadcast
Leader delegates the same task to all members, then synthesizes
tasks
Leader runs a task list loop until the goal is complete
In TeamMode.tasks, the leader uses task management tools to build and execute a shared task list, looping until the goal is complete or max_iterations is reached.Teams can pause for human-in-the-loop requirements (e.g., approvals or user input). When a run requires confirmation, the run returns with pending requirements so you can collect input or resolve approvals before continuing.
Paused runs return status=RunStatus.paused and requirements on the TeamRunOutput.
Human oversight is a control path. Runs can pause for confirmation or external execution and resume when requirements are resolved.
When using arun() with multiple members, they execute concurrently. Member events arrive as they happen, not in order.Disable member event streaming with stream_member_events=False:
Copy
Ask AI
team = Team( name="Research Team", members=[news_agent, finance_agent], model=OpenAIResponses(id="gpt-4o"), stream_member_events=False)
For development, use print_response() to display formatted output:
Copy
Ask AI
team.print_response("What are the top AI stories?", stream=True)# Show member responses tooteam.print_response("What are the top AI stories?", show_members_responses=True)