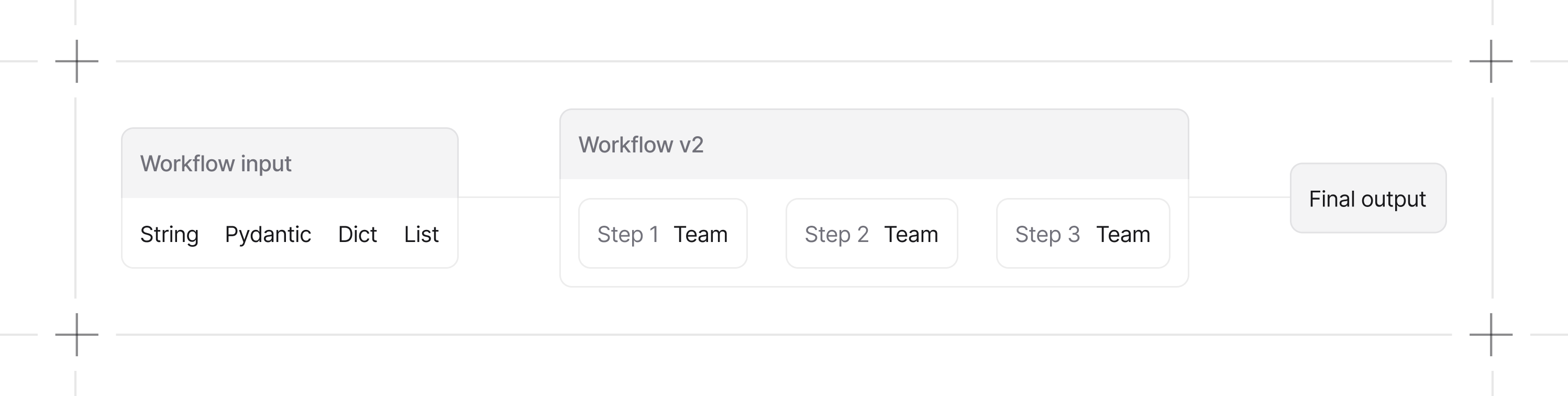
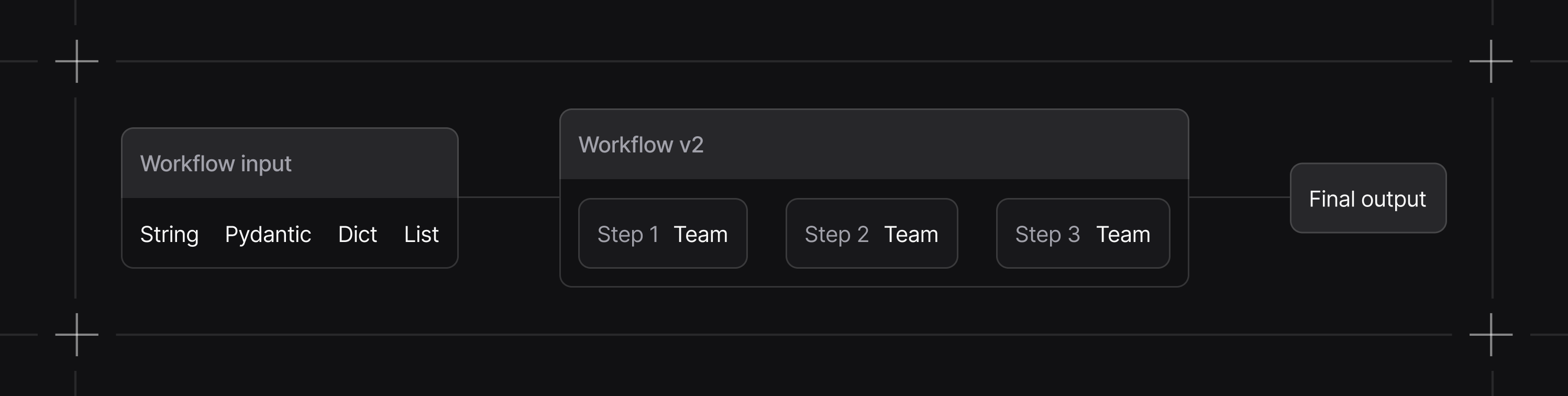
Your First Workflow
Here’s a simple workflow that takes a topic, researches it, and writes an article:When to Use Workflows
Use a workflow when:- You need predictable, repeatable execution
- Tasks have clear sequential steps with defined inputs and outputs
- You want audit trails and consistent results across runs
What Can Be a Step?
| Step Type | Description |
|---|---|
| Agent | Individual AI executor with specific tools and instructions |
| Team | Coordinated group of agents for complex sub-tasks |
| Function | Custom Python function for specialized logic |
| Workflow | Nested workflow for composable, reusable sub-pipelines |
Controlling Workflows
Workflows support conditional logic, parallel execution, loops, and conversational interactions. See the guides below for details.Guides
Build Workflows
Define steps, inputs, and outputs.
Run Workflows
Execute workflows and handle responses.
Conversational Workflows
Enable chat interactions on your workflows.