Evals
Accuracy Evals
Learn how to evaluate your Agno Agents and Teams for accuracy using LLM-as-a-judge methodology with input/output pairs.
Accuracy evals aim at measuring how well your Agents and Teams perform against a gold-standard answer.
You will provide an input and the ideal, expected output. Then the Agent’s real answer will be compared against the given ideal output.
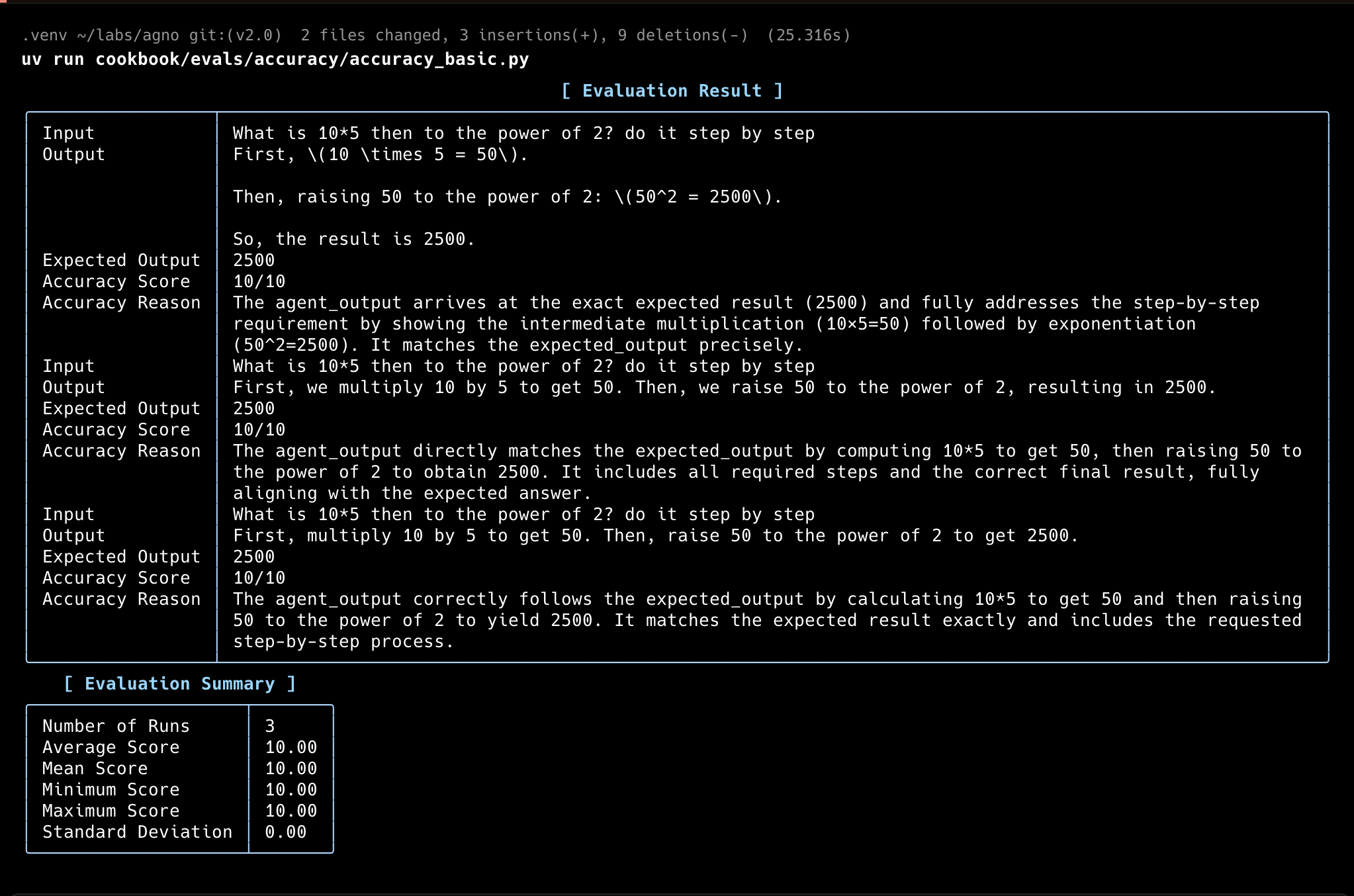
Basic Example
In this example, theAccuracyEval will run the Agent with the input, then use a different model (o4-mini) to score the Agent’s response according to the guidelines provided.
accuracy.py
Evaluator Agent
To evaluate the accuracy of the Agent’s response, we use another Agent. This strategy is usually referred to as “LLM-as-a-judge”. You can adjust the evaluator Agent to make it fit the criteria you want to evaluate:Accuracy with Tools
You can also run theAccuracyEval with tools.
accuracy_with_tools.py
Accuracy with given output
For comprehensive evaluation, run with a given output:accuracy_with_given_answer.py
Accuracy with asynchronous functions
Evaluate accuracy with asynchronous functions:async_accuracy.py
Accuracy with Teams
Evaluate accuracy with a team:accuracy_with_team.py
Accuracy with Number Comparison
This example demonstrates evaluating an agent’s ability to make correct numerical comparisons, which can be tricky for LLMs when dealing with decimal numbers:accuracy_comparison.py
Usage
1
Create a virtual environment
Open the
Terminal and create a python virtual environment.2
Install libraries
3
Run Basic Accuracy Example
4
Test Accuracy with Tools
5
Test with Given Answer
6
Test Async Accuracy
7
Test Team Accuracy
8
Test Number Comparison
Track Evals in your AgentOS
The best way to track your Agno Evals is with the AgentOS platform.evals_demo.py
1
Run the Evals Demo
2
View the Evals Demo
Head over to https://os.agno.com/evaluation to view the evals.