> ## Documentation Index
> Fetch the complete documentation index at: https://docs.agno.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Agent as Judge Evals
> Agent as Judge evals measure custom quality criteria for your Agents and Teams using LLM-as-a-judge methodology.
Agent as Judge evaluations let you define custom quality criteria and use an LLM to score your Agent's responses. You provide evaluation criteria (like "professional tone", "factual accuracy", or "user-friendliness"), and an evaluator model assesses how well the Agent's output meets those standards.
## Basic Example
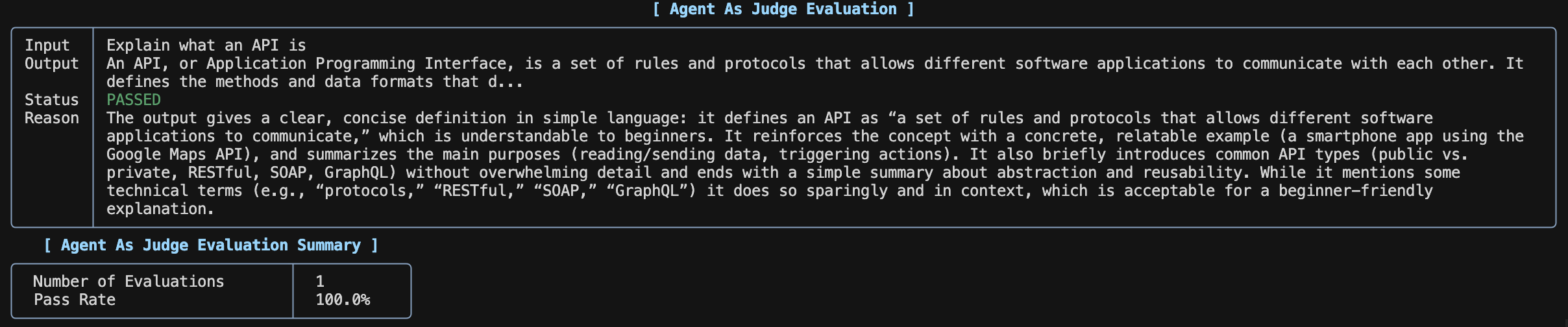
In this example, the `AgentAsJudgeEval` will evaluate the output of the Agent with their input, providing a score of the Agent's response according to the custom criteria provided.
```python agent_as_judge.py theme={null}
from agno.agent import Agent
from agno.db.sqlite import SqliteDb
from agno.eval.agent_as_judge import AgentAsJudgeEval
from agno.models.openai import OpenAIResponses
# Setup database to persist eval results
db = SqliteDb(db_file="tmp/agent_as_judge_basic.db")
agent = Agent(
model=OpenAIResponses(id="gpt-5.2"),
instructions="You are a technical writer. Explain concepts clearly and concisely.",
db=db,
)
response = agent.run("Explain what an API is")
evaluation = AgentAsJudgeEval(
name="Explanation Quality",
criteria="Explanation should be clear, beginner-friendly, and use simple language",
scoring_strategy="numeric", # Score 1-10
threshold=7, # Pass if score >= 7
db=db,
)
result = evaluation.run(
input="Explain what an API is",
output=str(response.content),
print_results=True,
)
```
### Custom Evaluator Agent
You can use a custom agent to evaluate responses with specific instructions:
```python agent_as_judge_custom_evaluator.py theme={null}
from agno.agent import Agent
from agno.eval.agent_as_judge import AgentAsJudgeEval
from agno.models.openai import OpenAIResponses
agent = Agent(
model=OpenAIResponses(id="gpt-5.2"),
instructions="Explain technical concepts simply.",
)
response = agent.run("Explain what an API is")
# Create a custom evaluator with specific instructions
custom_evaluator = Agent(
model=OpenAIResponses(id="gpt-5.2"),
description="Strict technical evaluator",
instructions="You are a strict evaluator. Only pass exceptionally clear and accurate explanations.",
)
evaluation = AgentAsJudgeEval(
name="Technical Accuracy",
criteria="Explanation must be technically accurate and comprehensive",
evaluator_agent=custom_evaluator,
)
result = evaluation.run(
input="Explain what an API is",
output=str(response.content),
print_results=True,
print_summary=True,
)
```
 ## Params
| Parameter | Type | Default | Description |
| --------------------------- | -------------------------------------- | ---------- | ------------------------------------------------------------------------- |
| `criteria` | `str` | `""` | The evaluation criteria describing what makes a good response (required). |
| `scoring_strategy` | `Literal["numeric", "binary"]` | `"binary"` | Scoring mode: `"numeric"` (1-10 scale) or `"binary"` (pass/fail). |
| `threshold` | `int` | `7` | Minimum score to pass (only used for numeric strategy). |
| `on_fail` | `Optional[Callable]` | `None` | Callback function triggered when evaluation fails. |
| `additional_guidelines` | `Optional[Union[str, List[str]]]` | `None` | Extra evaluation guidelines beyond the main criteria. |
| `name` | `Optional[str]` | `None` | Name for the evaluation. |
| `model` | `Optional[Model]` | `None` | Model to use for judging (defaults to gpt-5-mini if not provided). |
| `evaluator_agent` | `Optional[Agent]` | `None` | Custom agent to use as evaluator. |
| `print_summary` | `bool` | `False` | Print summary of evaluation results. |
| `print_results` | `bool` | `False` | Print detailed evaluation results. |
| `file_path_to_save_results` | `Optional[str]` | `None` | File path to save evaluation results. |
| `debug_mode` | `bool` | `False` | Enable debug mode for detailed logging. |
| `db` | `Optional[Union[BaseDb, AsyncBaseDb]]` | `None` | Database to store evaluation results. |
| `telemetry` | `bool` | `True` | Enable telemetry. |
| `run_in_background` | `bool` | `False` | Run evaluation as background task (non-blocking). |
## Methods
### run() / arun()
Run the evaluation synchronously (`run()`) or asynchronously (`arun()`).
| Parameter | Type | Default | Description |
| --------------- | -------------------------------- | ------- | ------------------------------------------------ |
| `input` | `Optional[str]` | `None` | Input text for single evaluation. |
| `output` | `Optional[str]` | `None` | Output text for single evaluation. |
| `cases` | `Optional[List[Dict[str, str]]]` | `None` | List of input/output pairs for batch evaluation. |
| `print_summary` | `bool` | `False` | Print summary of evaluation results. |
| `print_results` | `bool` | `False` | Print detailed evaluation results. |
Provide either (`input`, `output`) for single evaluation OR `cases` for batch evaluation, not both.
## Examples
Basic usage with numeric scoring and failure callbacks
Automatic evaluation after agent runs
## Developer Resources
## Params
| Parameter | Type | Default | Description |
| --------------------------- | -------------------------------------- | ---------- | ------------------------------------------------------------------------- |
| `criteria` | `str` | `""` | The evaluation criteria describing what makes a good response (required). |
| `scoring_strategy` | `Literal["numeric", "binary"]` | `"binary"` | Scoring mode: `"numeric"` (1-10 scale) or `"binary"` (pass/fail). |
| `threshold` | `int` | `7` | Minimum score to pass (only used for numeric strategy). |
| `on_fail` | `Optional[Callable]` | `None` | Callback function triggered when evaluation fails. |
| `additional_guidelines` | `Optional[Union[str, List[str]]]` | `None` | Extra evaluation guidelines beyond the main criteria. |
| `name` | `Optional[str]` | `None` | Name for the evaluation. |
| `model` | `Optional[Model]` | `None` | Model to use for judging (defaults to gpt-5-mini if not provided). |
| `evaluator_agent` | `Optional[Agent]` | `None` | Custom agent to use as evaluator. |
| `print_summary` | `bool` | `False` | Print summary of evaluation results. |
| `print_results` | `bool` | `False` | Print detailed evaluation results. |
| `file_path_to_save_results` | `Optional[str]` | `None` | File path to save evaluation results. |
| `debug_mode` | `bool` | `False` | Enable debug mode for detailed logging. |
| `db` | `Optional[Union[BaseDb, AsyncBaseDb]]` | `None` | Database to store evaluation results. |
| `telemetry` | `bool` | `True` | Enable telemetry. |
| `run_in_background` | `bool` | `False` | Run evaluation as background task (non-blocking). |
## Methods
### run() / arun()
Run the evaluation synchronously (`run()`) or asynchronously (`arun()`).
| Parameter | Type | Default | Description |
| --------------- | -------------------------------- | ------- | ------------------------------------------------ |
| `input` | `Optional[str]` | `None` | Input text for single evaluation. |
| `output` | `Optional[str]` | `None` | Output text for single evaluation. |
| `cases` | `Optional[List[Dict[str, str]]]` | `None` | List of input/output pairs for batch evaluation. |
| `print_summary` | `bool` | `False` | Print summary of evaluation results. |
| `print_results` | `bool` | `False` | Print detailed evaluation results. |
Provide either (`input`, `output`) for single evaluation OR `cases` for batch evaluation, not both.
## Examples
Basic usage with numeric scoring and failure callbacks
Automatic evaluation after agent runs
## Developer Resources